
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- mock
- dotenv
- DP
- 다형성
- PostgreSQL
- 객체지향
- 클라우드
- package
- bfs
- github
- GOF
- 추상화
- Secret
- npm
- CSS
- git
- 서브셋폰트
- netlify
- 동적계획법
- 메모이제이션
- 상속
- process.env
- MariaDB
- azure
- 디자인 패턴
- AOP
- Solid
- dfs
- Java
- 캡슐화
- Today
- Total
이것저것 해보기🌼
[AWS SageMaker]M/L Data Wrangler 핸즈온 본문
오늘은 아마존 공식 가이드를 활용해 AWS SageMaker Data Wrangler 실습을 진행해보았다.
SageMaker는 쉽게말해 콘솔 형태로, 손쉽게 ML training이 가능한 AWS 서비스이다.
나는 교육기회를 받게 되어서, 이벤트 엔진을 활용하였지만
개인 계정으로 수행하게 되면 과금에 유의해야한다!
공식 가이드 : https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler-getting-started.html
1. 세이지 메이커 스튜디오 생성하기
우선 세이지 메이커 스튜디오를 생성해보자.
AWS 서비스중 SageMaker를 선택한 후 아래와 같이 새로 만든다.
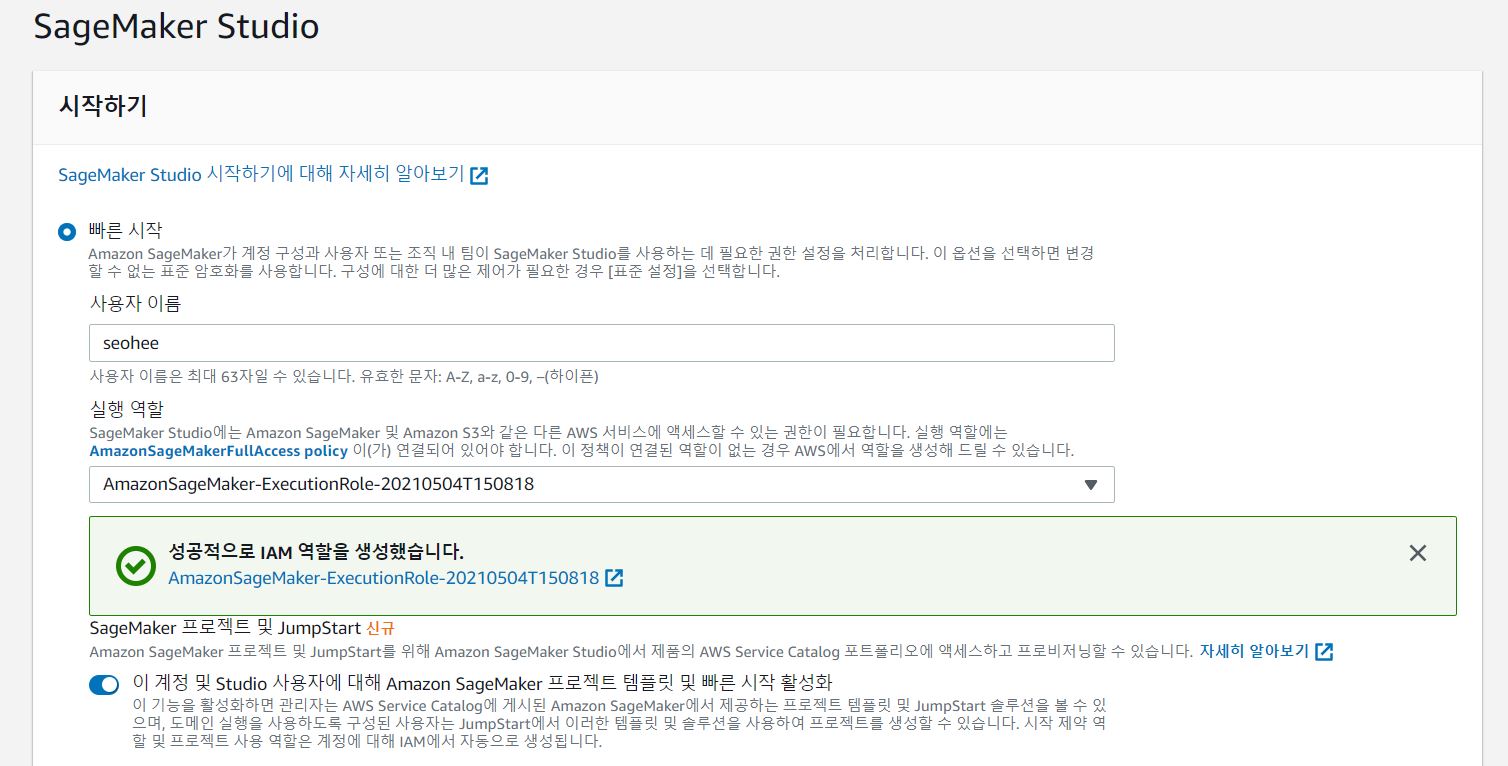
실행 역할은 새로운 역할을 생성하고, 기본 선택되어있는 옵션대로 role을 생성했다.
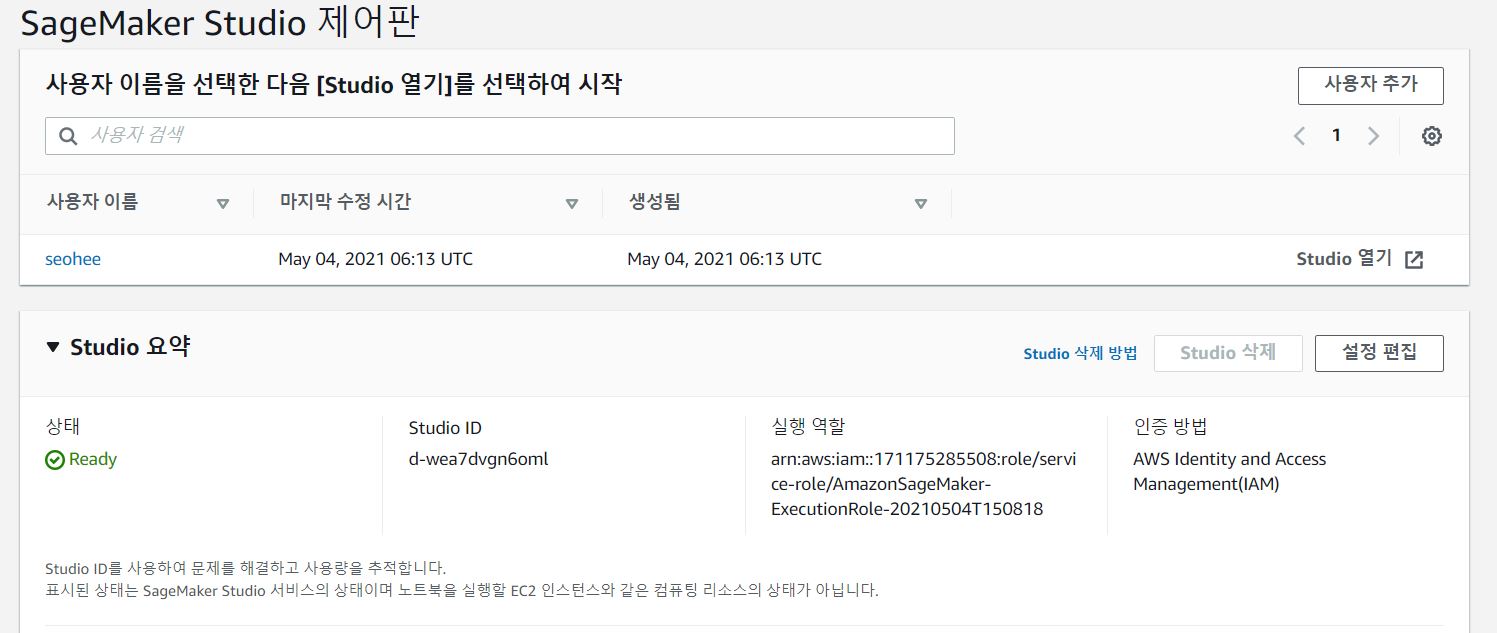
이와 같이 생성하면 대략 1분 정도 Pending 상태이다가, 아래처럼 Ready 상태로 바뀌게 된다.
생성된 사용자이름 가장 오른쪽의 Studio 열기를 클릭한다.
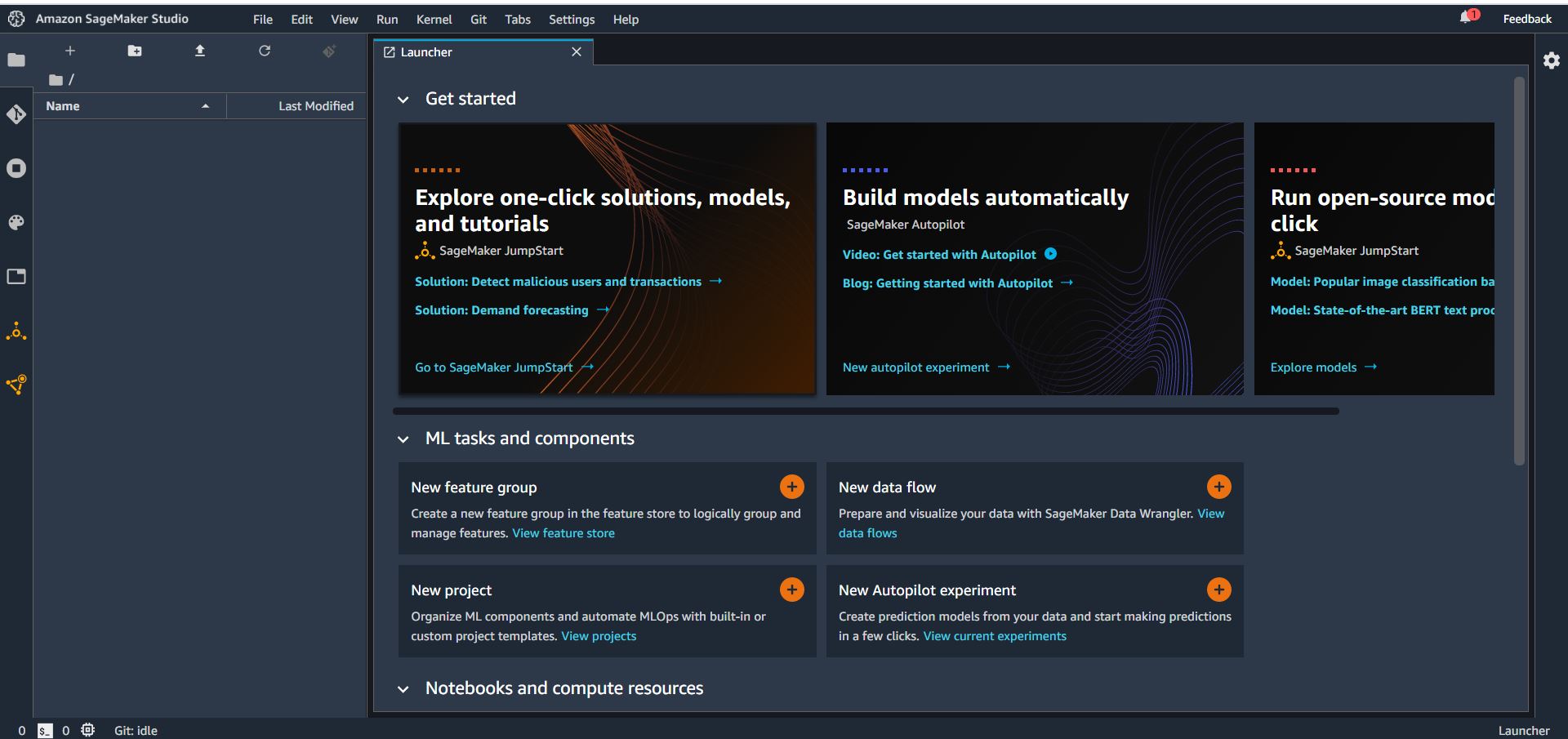
아래와 같이 크롬 새탭에 스튜디오 화면이 뜬다.
그럼 세이지메이커 스튜디오 준비 완료!
이제 S3 버킷을 생성해야한다.
2. S3 버킷 생성하기
서비스 중 S3를 선택한 후 아래와 같이 신규 생성을 완료한다.
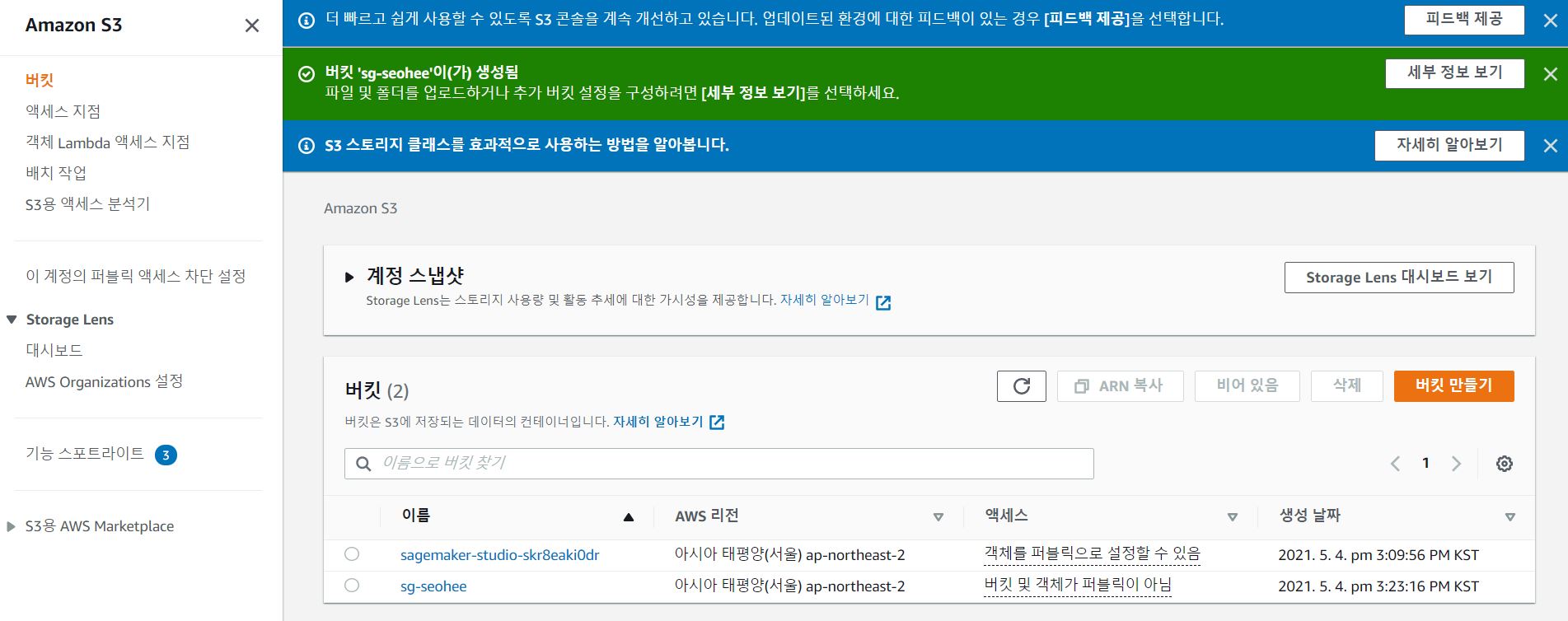
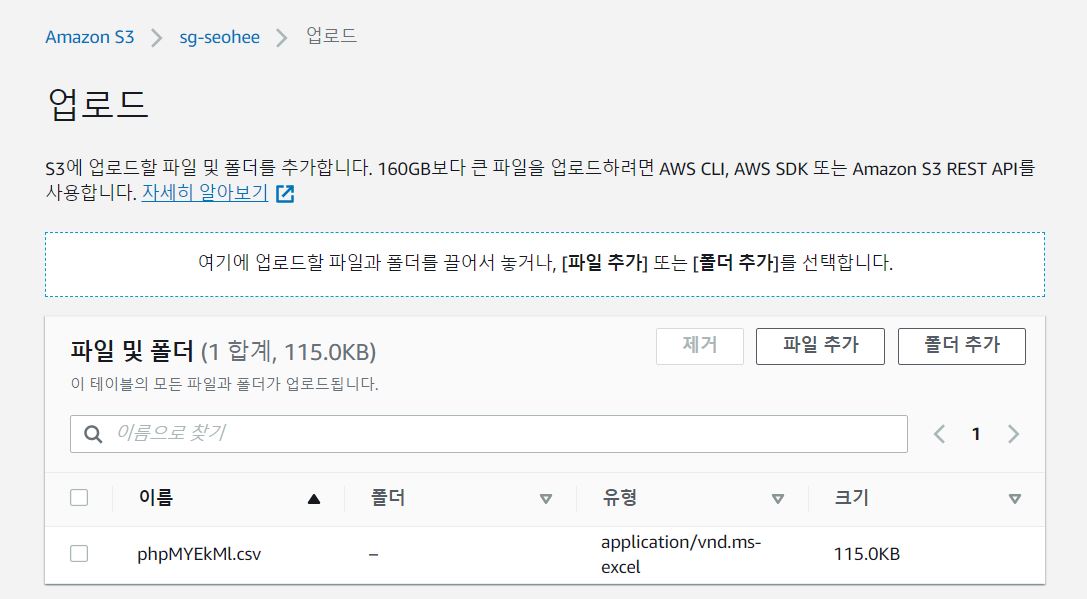
만든 S3에 실습에 사용할 데이터 파일을 업로드한다.
(이번실습에서는 https://www.openml.org/d/40945 에서 CSV 로 다운로드받은 파일을 사용하였다)
이 데이터는 타이타닉 생존 데이터로, 나이, 성별, 객실클래스 등 정보와 생존여부가 저장되어있다.
3. SageMaker Studio 에서 실습 진행하기
이제 세이지 메이커 스튜디오에서 M/L 실습을 진행해보면 된다.
먼저 File > New > Flow 를 통해 New Data Flow를 실행한다. 5분 정도 후 완료된다.
완료되면 Connecting to engine 메시지가 사라지고 아래와 같은 화면이 나타난다.
Import 메뉴에서 S3를 선택한다.
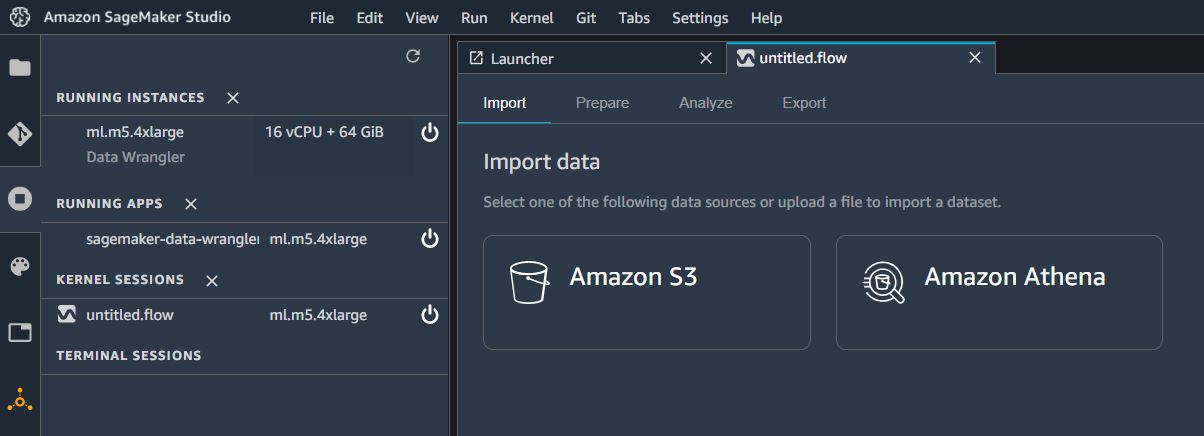
2번 단계에서 S3 버킷에 업로드했던 데이터 파일을 선택한다.
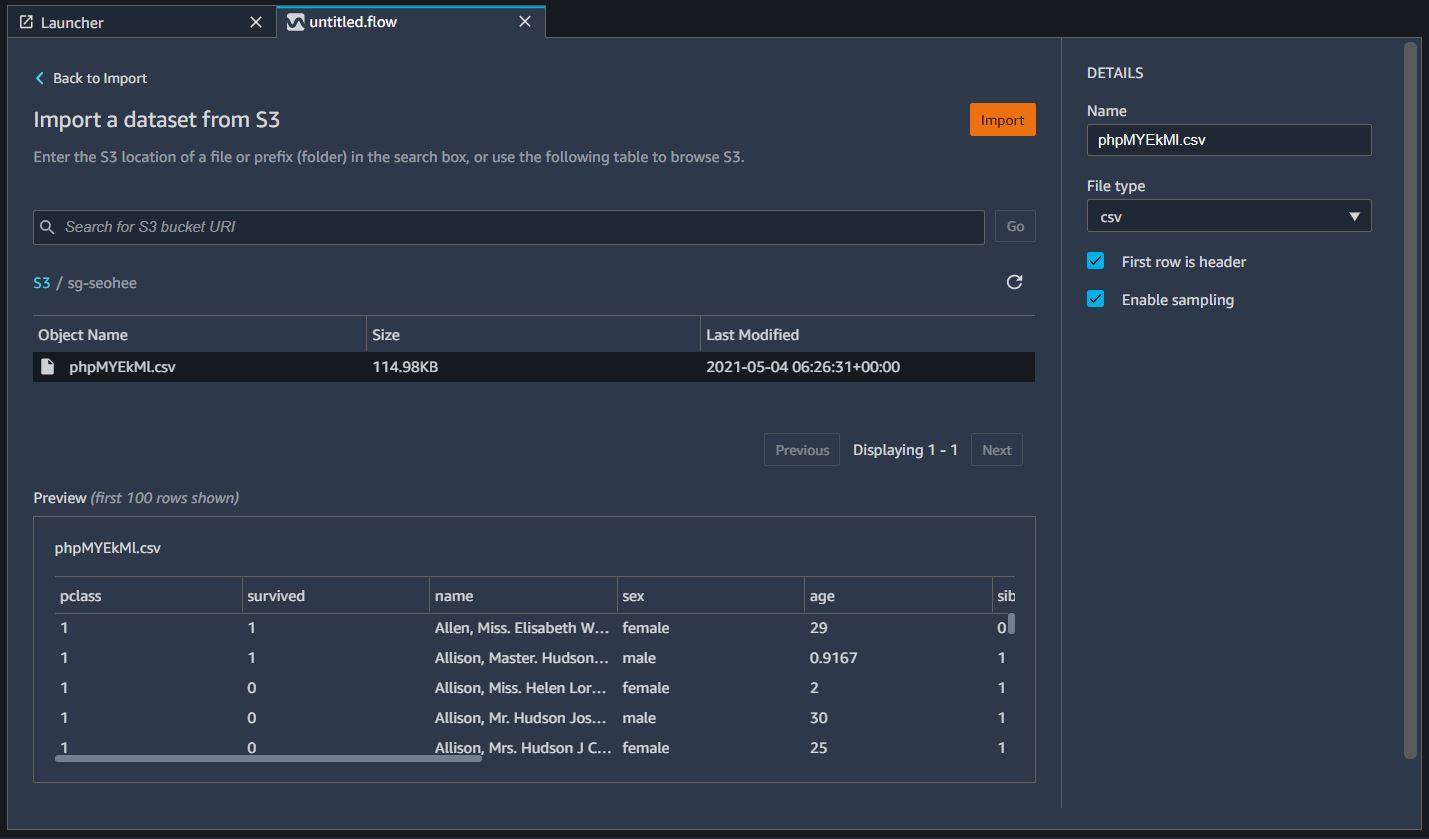
자동으로 prepare 탭으로 이동되면, 아래와 같이 Add analysis를 선택한다.
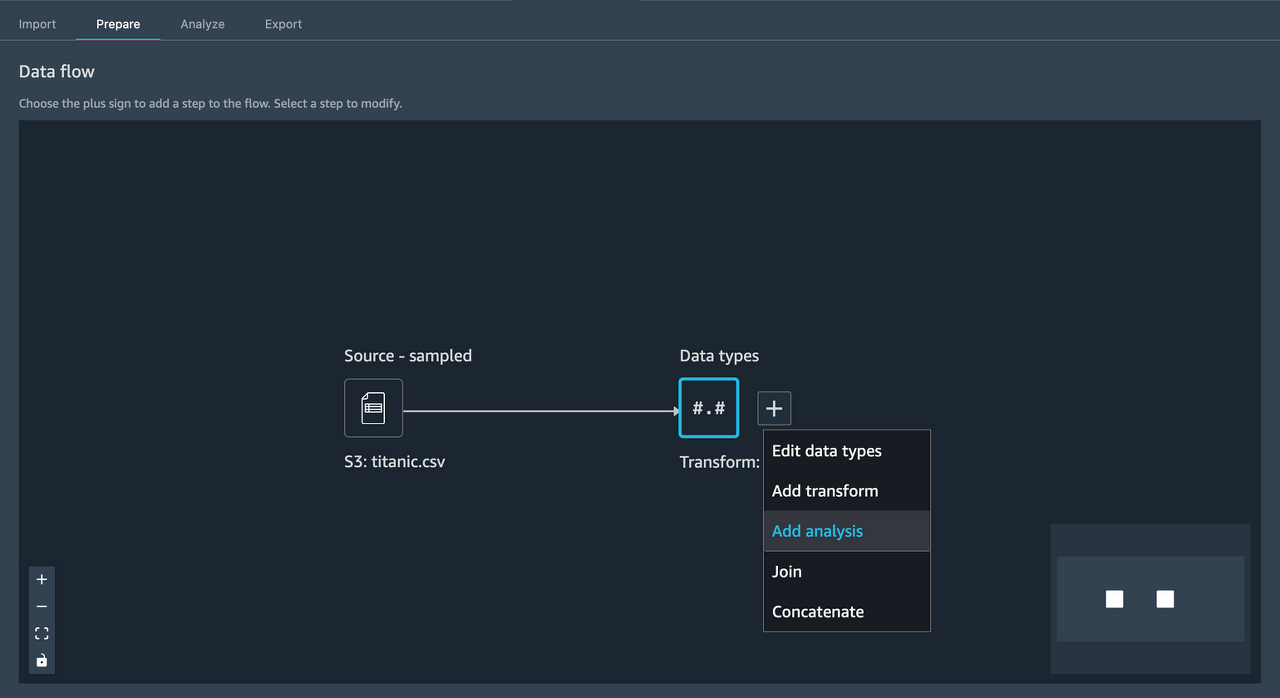
Table Summary 선택 후 Preview로 간단한 정보를 미리볼수 있다. (평균값, 최소값, 최대값 등등..)
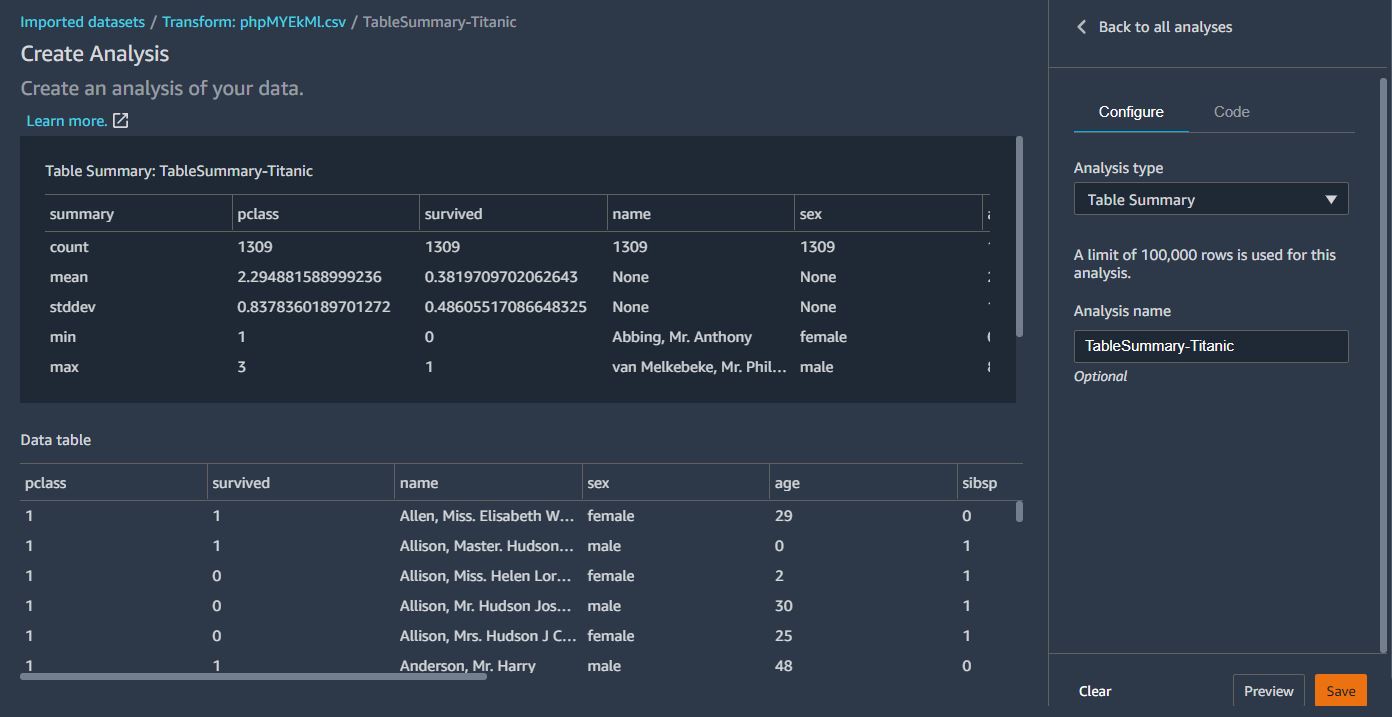
create 버튼을 통해 해당 정보를 저장한다.
또다시 Add analytics 를 통해 이번에는 Histogram을 생성해본다.
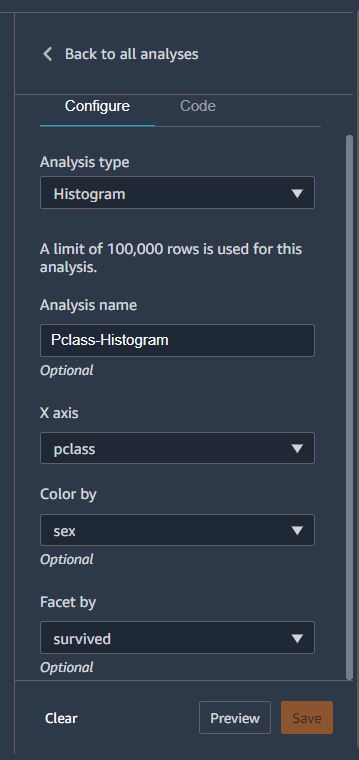
위와 같이 히스토그램을 생성하면 성별에 따른 생존여부를 살펴볼수 있다.
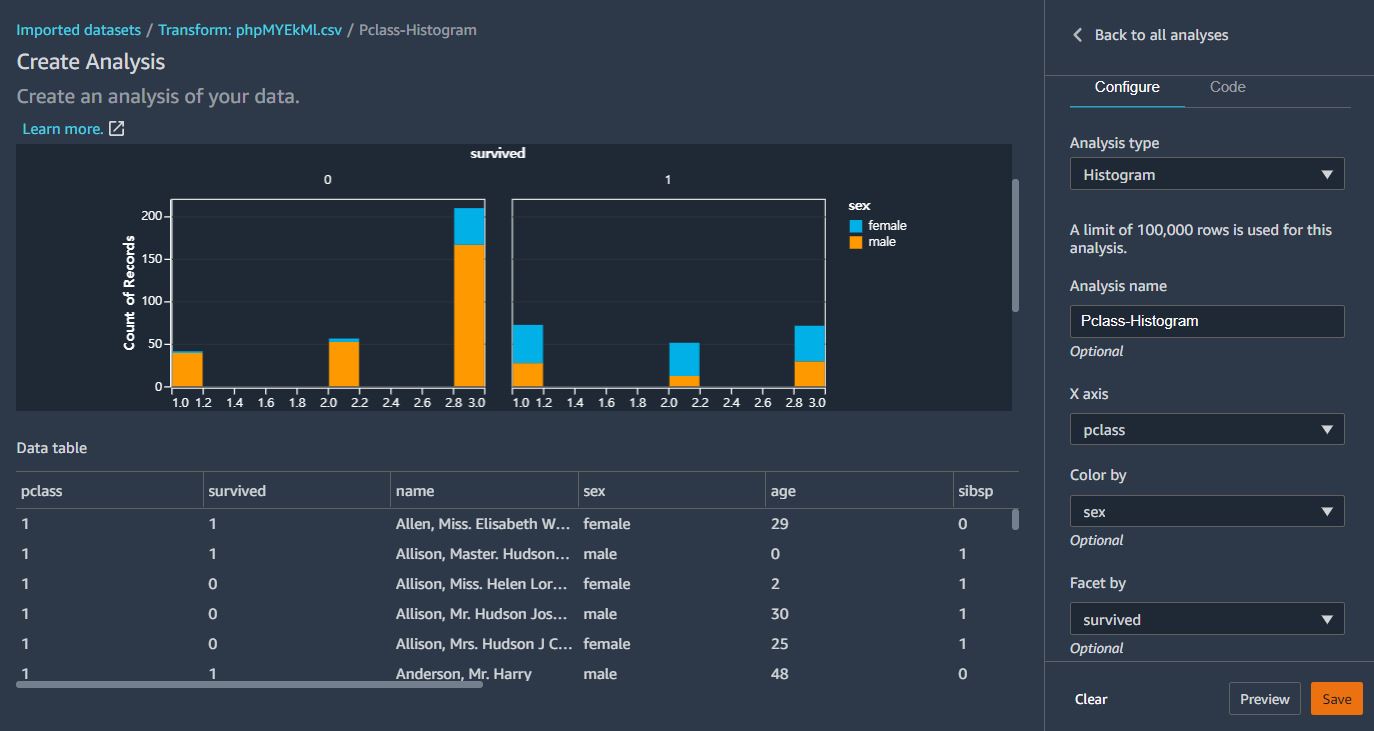
이번에는 사용하지 않을 컬럼에 대해 삭제해볼것이다.
Prepare 탭에서 Add transform을 선택한다.
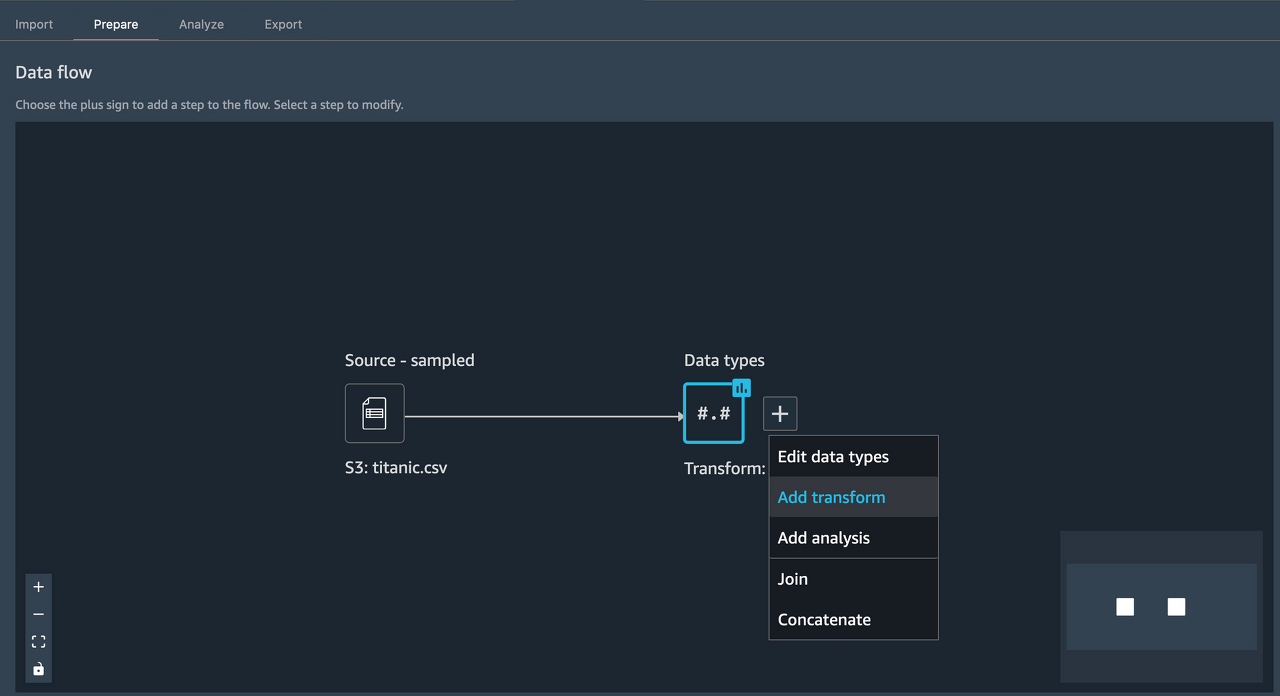
아래와 같은 Python 코드를 Python(Pandas)를 선택한 후 붙여넣기한다.
cols = ['name', 'ticket', 'cabin', 'sibsp', 'parch', 'home.dest','boat', 'body']
df = df.drop(cols, axis=1)
마찬가지로 Preview로 해당 칼럼들이 삭제되었는지 확인후 Add를 수행한다.
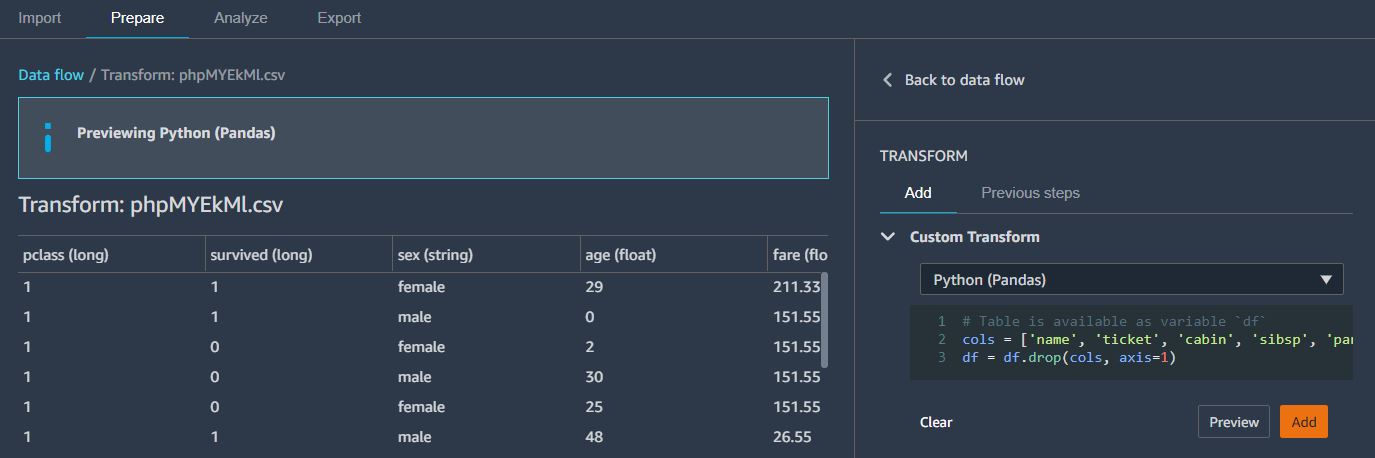
데이터셋의 결측치를 확인하기 위해서는 아래와 같은 코드를 Add Transform으로 추가하여 주면 된다.
df.info()
(아래 나타난 df 정보를 확인해보는 의미이기 때문에 굳이 Add까지는 하지 않아도 된다)
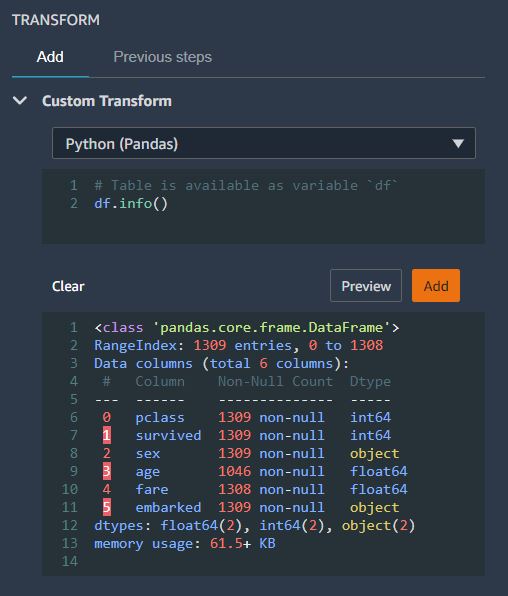
위 df info 중, 전체 데이터 갯수는 1309 개이지만, age 칼럼의 값은 1046 개이고, fare 칼럼의 값은 1308 개이다.
따라서 두 칼럼에는 몇몇 데이터 값이 저장되지 않았다는 사실을 알 수 있다.
이렇게 값이 없는 일부 데이터를 정제해보도록 한다.
이번에는 Add Transform에서 Handle missing 탭에서 아래와 같이 선택한다. 그럼 age 칼럼의 missing data를 제외하게 된다.
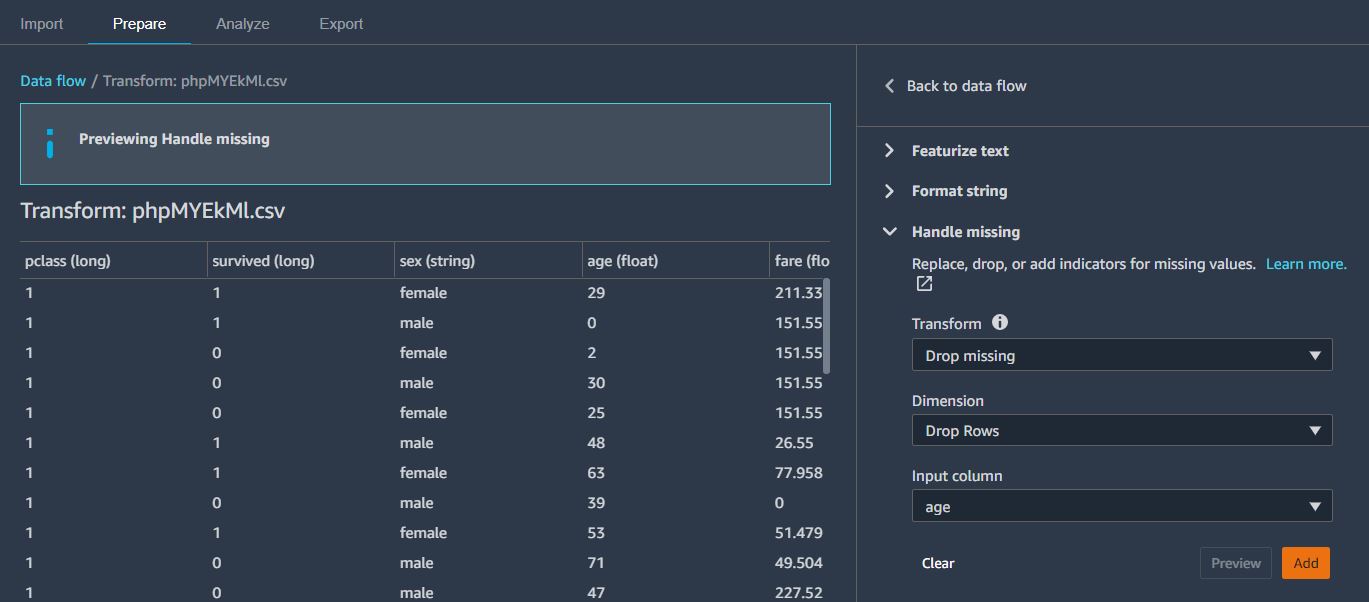
마찬가지로, fare에 해당하는 missing value도 제거해주었다.
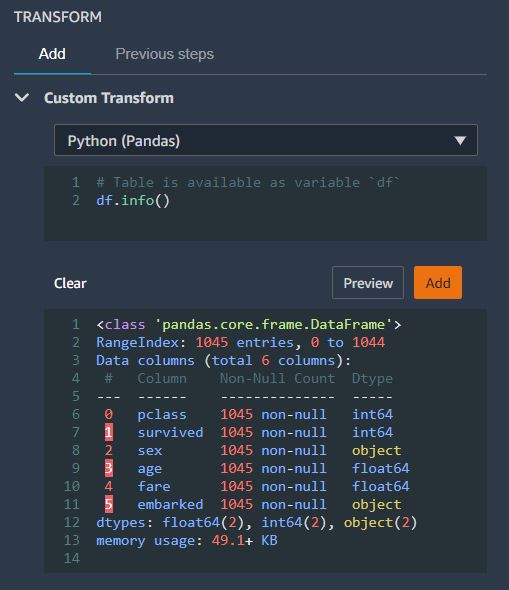
다시 df.info() 를 수행해보면 모든 칼럼 값이 1045 개로, missing value가 제거된 것을 확인해볼 수 있다.
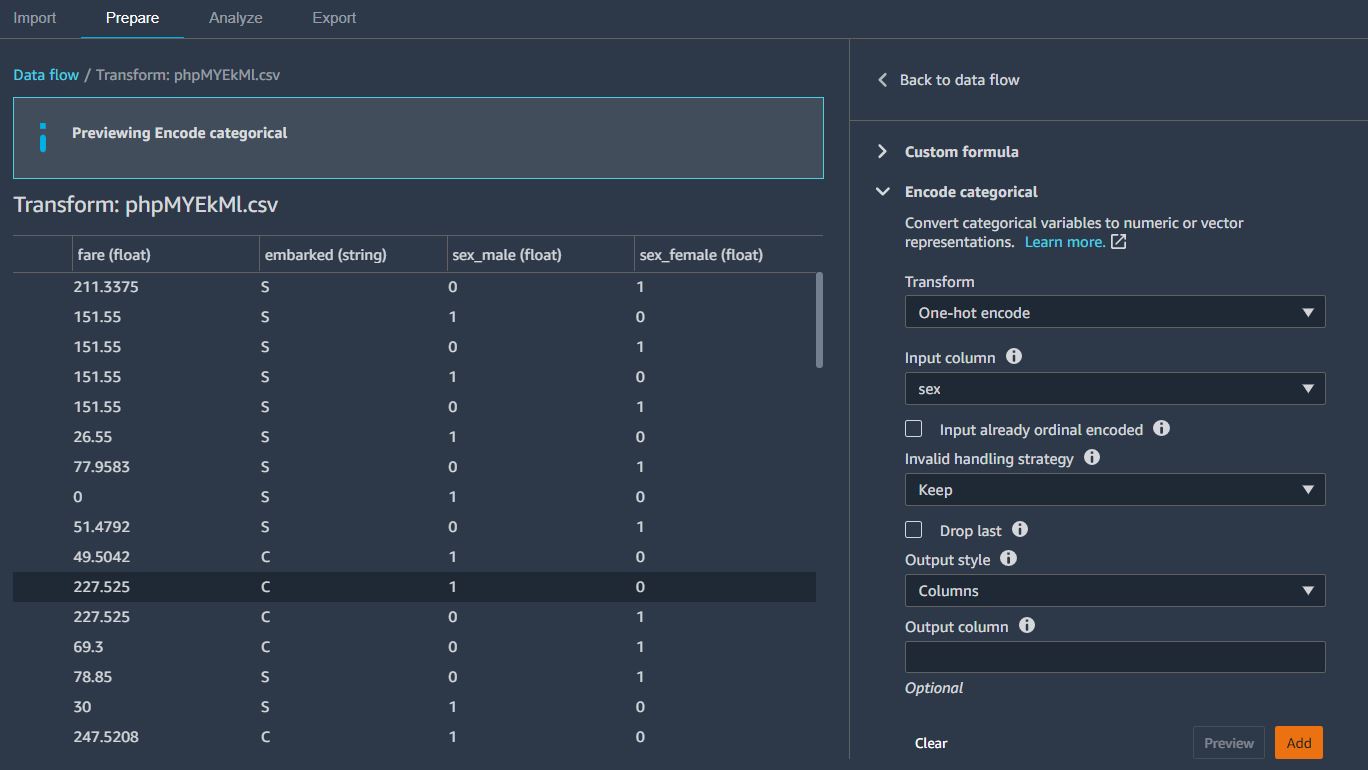
이번에는 sex 컬럼에 대해 인코딩을 수행한다. (-> 인코딩은 왜 수행하는것일까?)
Encode categorical 탭에서 아래와 같이 값을 넣고 Preview -> Add를 수행한다.
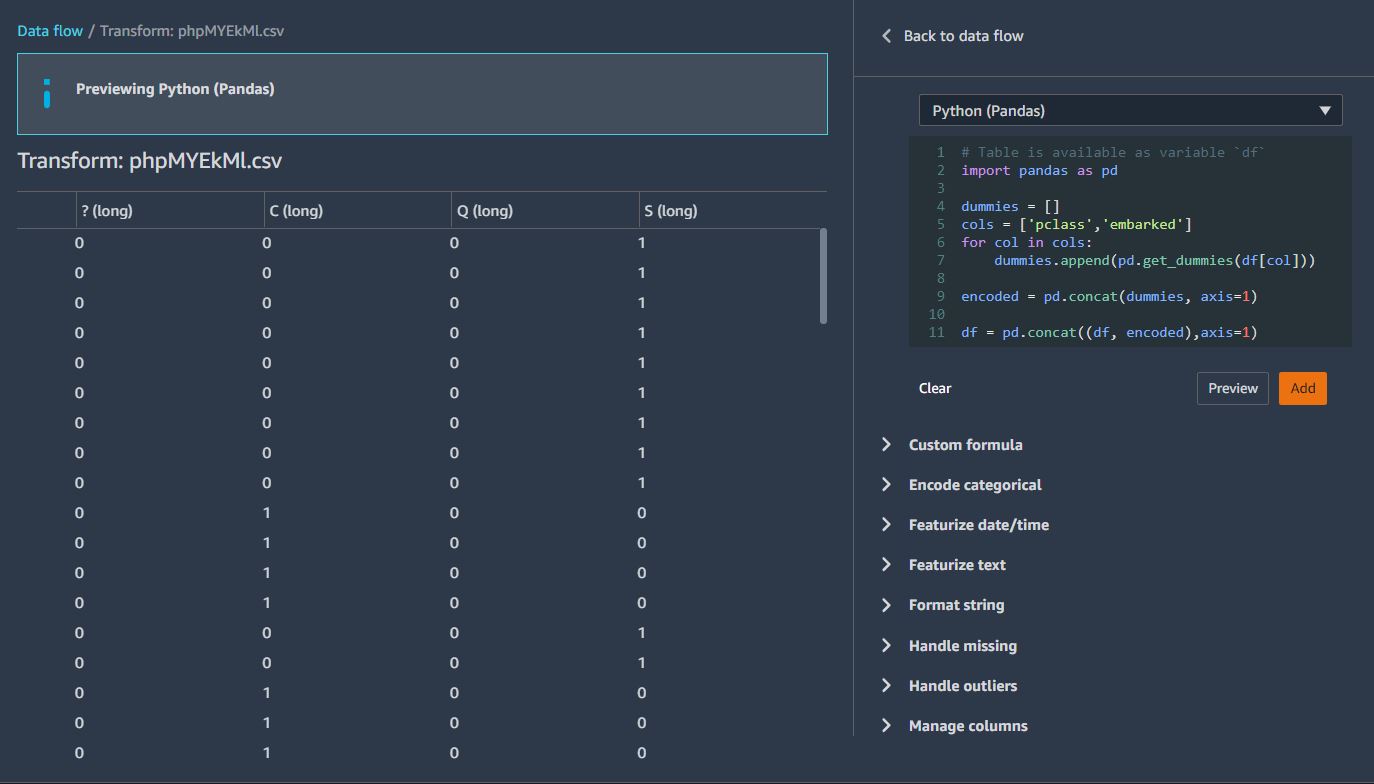
pclass 와 embarked 칼럼을 커스텀코드로 등록한다.
아래와 같은 코드를 Python(Pandas) 로 추가한다.
import pandas as pd
dummies = []
cols = ['pclass','embarked']
for col in cols:
dummies.append(pd.get_dummies(df[col]))
encoded = pd.concat(dummies, axis=1)
df = pd.concat((df, encoded),axis=1)
이제 SQL을 이용하여 최종 feature 컬럼을 선택한다. Custom Transform에서 Python(PySpark SQL)를 선택하고 다음 코드를 추가합니다.
SELECT survived, age, fare, 1, 2, sex_male, C, Q, S FROM df;
전체적인 Steps 를 점검한 뒤, Export 탭으로 이동한다.
Steps 를 클릭해서 방금까지 만들었던 7개 스탭 중 가장 마지막 스탭을 선택한다. 그러면 Export Step 버튼이 활성화된다.
Export Step을 클릭한 후 Python code를 선택하면 Python 코드로 자동 변환되어 저장되는 것을 확인해볼 수 있다.
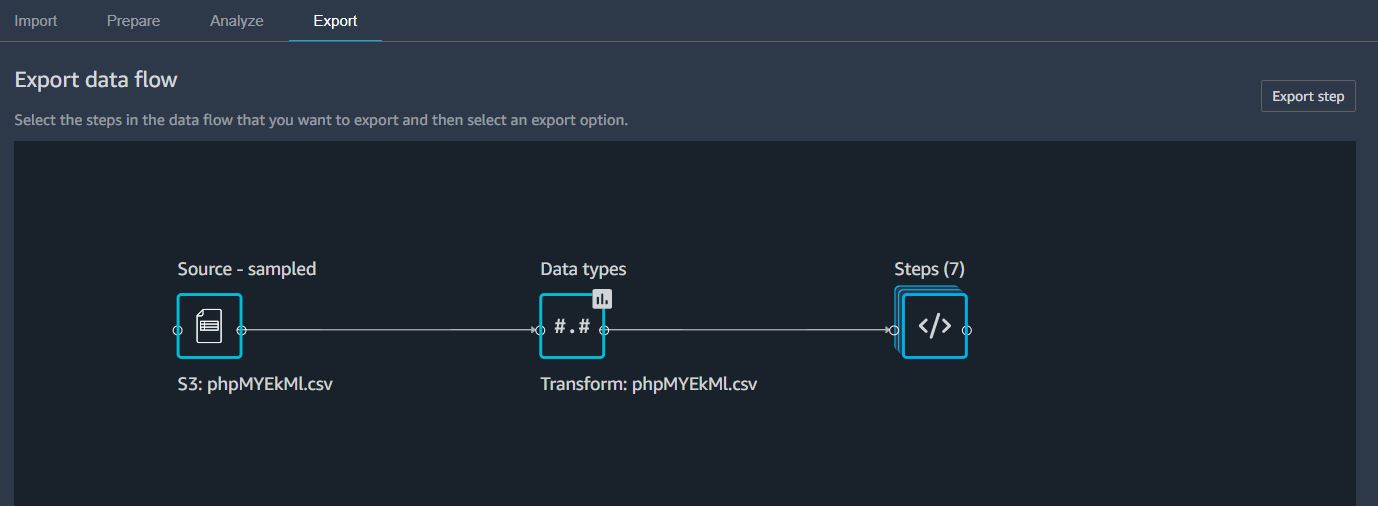
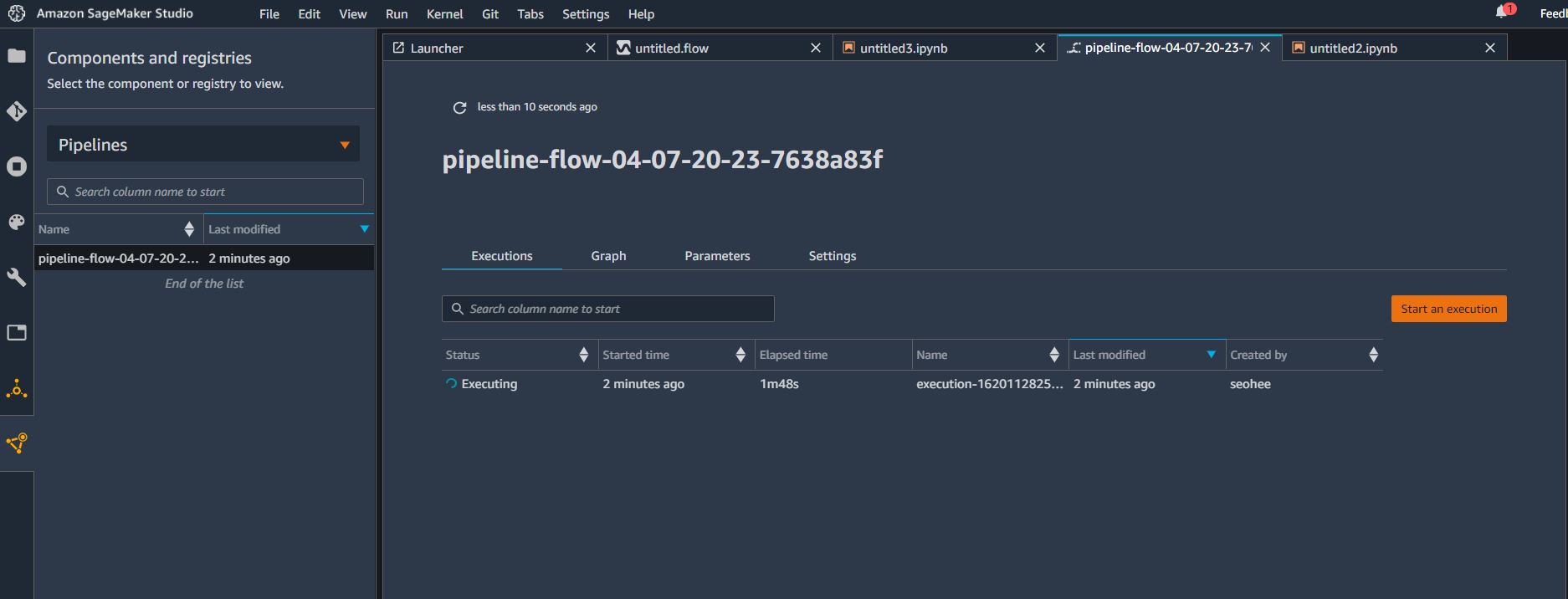
Export step 버튼을 클릭하고 이번에는 Pipeline을 선택한다.
이제 파이프라인 작업이 시작되고, 좌측메뉴의 가장 아래 아이콘(Components and registries)를 통해 실행중인 파이프라인을 확인해볼 수 있다.
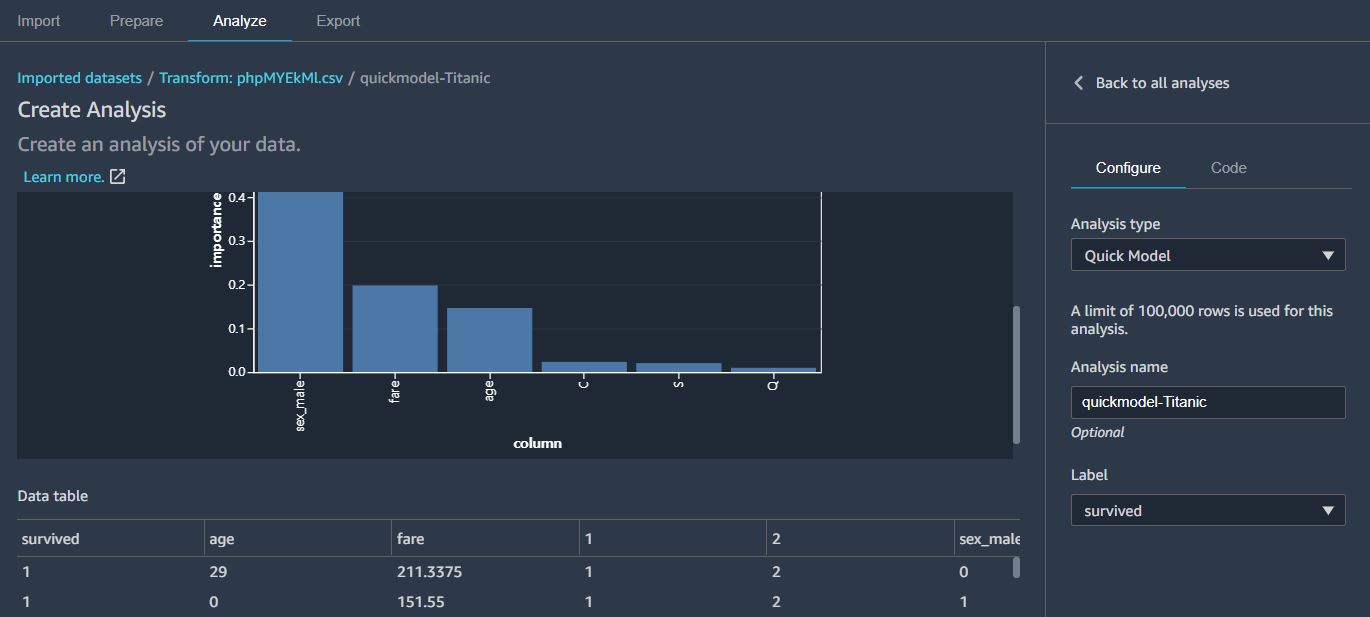
참고적으로, Add Analysis 를 통해 Quick Model로 분석하는 방법도 있다.
이렇게 하면 모든 칼럼들에 대해, 생존율에 영향을 많이 미치는 정도를 확인해 볼 수 있다.
이번에는 Export Steps에서 Save to S3 를 클릭하여, 내 S3 버킷에 결과를 저장해본다.
좌측 Pipelines 에서 방금 실행한 파이프라인을 선택하면 상세한 정보가 우측화면에 나타나고,
우측 화면의 Output 탭에서 S3에 저장되는 위치를 확인해볼 수 있다.
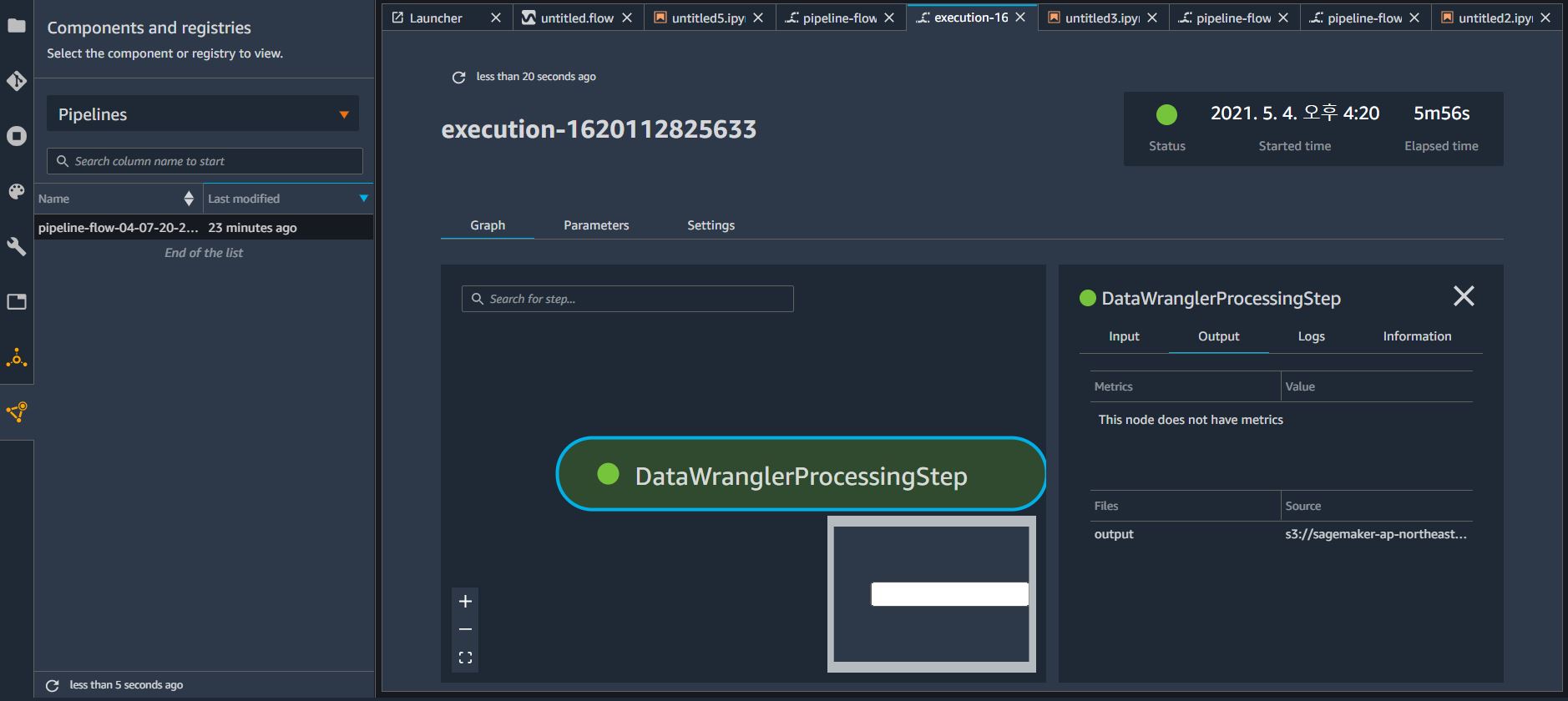
해당 S3 위치에서 생성된 폴더를 계속 들어가면 결과 데이터 CSV 파일이 저장된 것을 확인해볼 수 있다.
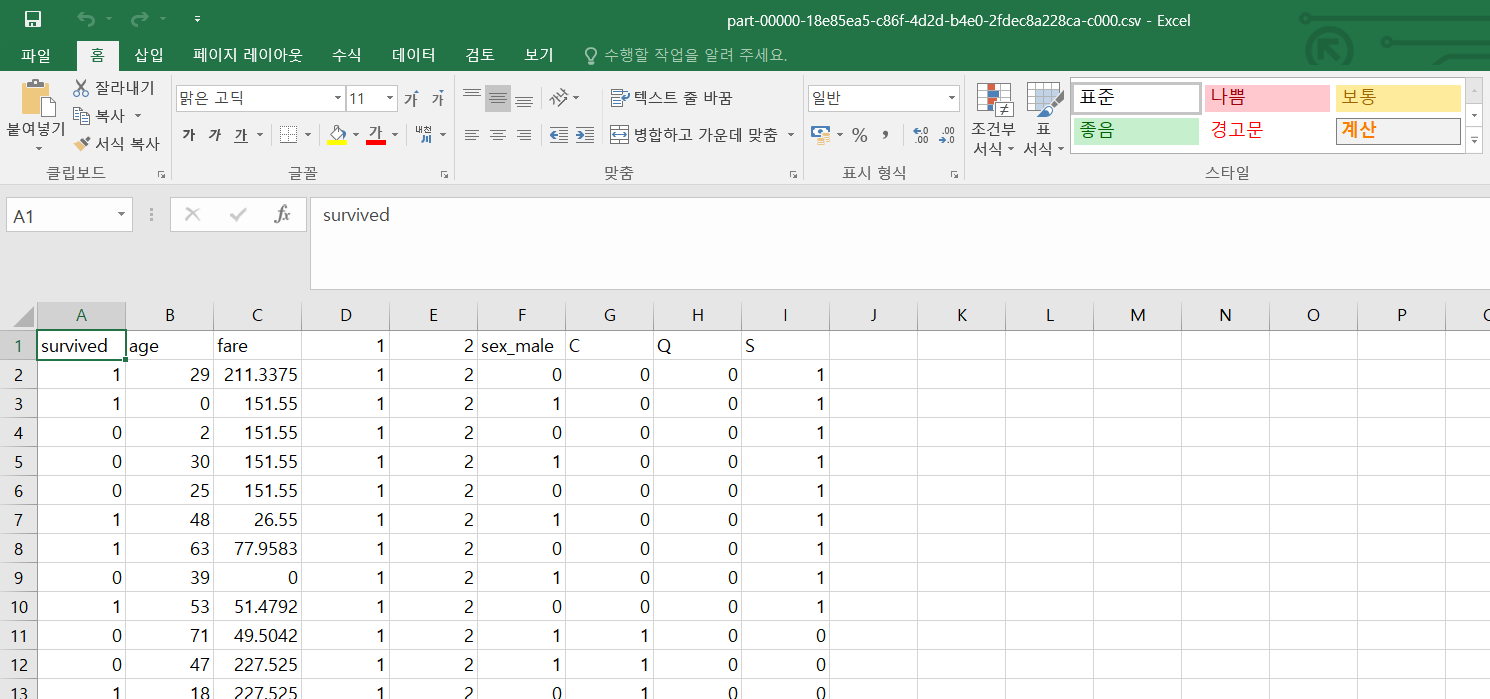
해당 파일을 다운로드하여 확인해보면, 내가 만든 Data flow대로 수행한 결과가 저장된것을 알수 있다.
SageMaker Data Wrangler 작업이 끝나면 불필요한 과금을 피하기 위해 인스턴스를 종료해주는것이 좋다.
이상으로 SageMaker 스튜디오를 활용해 ML 과제를 수행하는 방법에 대해 알아보았다.
대용량의 데이터를 csv 등의 형식으로 S3에 저장하고, 이를 SageMaker Studio 를 만들어서 기본적인 분석을 시도할 수 있고, 추가적인 데이터 정제와 내가 살펴보고 싶은 칼럼들을 인코딩하여
파이썬 코딩없이 자동적으로 실행하거나, 파이썬 코드로 저장도 해볼수 있다는 것을 알수 있었다.
대략적으로 어떻게 활용할 수 있겠다 라는 느낌은 왔지만 상세 단계들 (예를 들면 칼럼 인코딩) 을 어떨 때 수행하는 것인지 감이 안오는 부분도 있었다.
데이터를 통해 반복적으로 실습을 해보면서 알수 있을것 같다.
'AWS' 카테고리의 다른 글
| AWS Cloud 기본 개념 정리 (리전, AZ, VPC, EC2, ELB, 서브넷 등등) (0) | 2024.06.25 |
|---|---|
| Linux(Ubuntu) EC2에서 Spring Boot 배포 스크립트 작성하기 (bash 오류 해결방법) (1) | 2024.05.01 |
| Docker Jenkins 버전 jdk 17로 바꾸기 (jenkins/jenkins:lts-jdk17) (0) | 2024.04.30 |
| EC2 환경에서 Docker를 이용해 Jenkins 설치하기 (0) | 2024.04.29 |
| 클라우드 컴퓨팅과 Azure (0) | 2021.11.01 |



